Dimensionality Reduction in Machine Learning
However, each feature that is added increases the complexity of the executable, which makes locating information using these powerful algorithms also complicated. The solution is dimensionality reduction, which consists of employing a set of techniques to remove excessive and unneeded features from Machine Learning models.
Dimensionality reduction also severely reduces the cost of machine learning and allows complex problems to be solved with simple models.
This technique is especially useful in predictive models, as they are datasets that contain a large number of input features, and makes their function more complicated.
What is Dimensionality?
We can say the number of features in our dataset is referred to as its dimensionality.
What is Dimensionality Reduction?
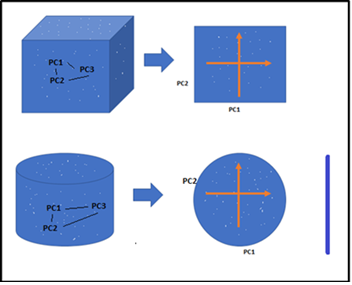
Dimensionality Reduction is the process of reducing the dimensions(features) of a given dataset. Let’s say if your dataset with a hundred columns/features and bringing the number of columns down to 20-25. In simple terms, you are converting the Cylinder/Sphere to a Circle or Cube into a Plane in the two-dimensional space as below figure.
He has drawn below the relationship clearly between Modle Performance and Number of Features(Dimensions). As the number of features increases, the number of data points also increases proportionally. the straight statement is that the more features will bring more data samples, So we have represented all combinations of features and their values.
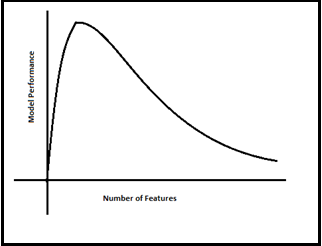
Now everyone in the room got the feel of what is “Curse Of Dimensionality” at a very high level.
Dimensionality problems
Going into detail on the dimensionality problems that appear in Machine Learning models, we must first know that these models are responsible for assigning features to results. For example, a predictive weather model has a dataset of information collected from different sources. These sources include data on temperature, humidity, wind speed. Bus tickets purchased, traffic and amount of rainfall from different times at the same location. As can be seen, not all data are relevant for weather forecasting.
Sometimes some features are not related to the target variable. Other features may be correlated with the target variable, but have no specific relationship to it. There may also be links between the feature and the target variable, but the effect is insignificant. In the above example, it is clear which characteristics are useful and which are not, but in other problems the difference may not be obvious and may require more data analysis.
Dimensionality reduction may not seem to make sense, because when too many features are present, a more complex model with more training data and more computational power will also be needed to train the model properly. However, models do not understand chance and try to assign any feature included in their dataset to the target variable, even if there is no chance relationship, generating erroneous models.
How to reduce dimensionality?
A common aspect is to use scatter plots and heat maps to visualise the covariance of different features, i.e., these tools are used to find out if two features are highly related to each other and if they will have a similar effect on the target variable, to determine that it is not necessary to include both in the model, eliminating one of them without negatively impacting performance. Similarly, variables that do not contribute information to the target variable are removed.
An example might be a data set of 25 columns that can be represented by only 7 of them, capable of representing 95% of the effect on the target variable. Thus, up to 18 functions can be eliminated, simplifying the machine learning model without losing efficiency.
Generally, when dimensionality reduction occurs, up to 15% of the variability in the original data is lost, but it brings with it advantages such as shorter training time, requires less computational resources and increases the overall performance of the algorithms. In addition, dimensionality reduction solves the problem of overfitting. When there are many features, models become more complex and tend to over-fit; thanks to reduction, this problem disappears.
Benefits and disadvantages of dimensionality reduction techniques
Some of the main benefits of applying the dimensionality reduction technique are the following:
- Reducing the dimensions of the features implies a reduction in the space required to store the dataset, because the dataset is also reduced.
- The model training time is shorter for reduced dimensions.
- Faster data visualisation is facilitated by reducing the number of features in the dataset.
- Redundant features in the multicollinearity domain disappear.
Dimensionality reduction also has certain disadvantages which are mentioned below, although the advantages are greater:
- Some data may be lost due to dimensionality reduction.
- In the PCA dimensionality reduction technique, the principal components to be considered are sometimes not known.
In short, having too many features will result in an inefficient Machine Learning model. However, the ability to reduce features through dimensionality reduction is a tool that can be used to create more optimised and efficient models.
Dimensionality reduction can be applied to different fields such as high dimensional data, speech recognition, data visualisation, noise reduction or signal processing, among others. It can also be used to transform non-linear data into a linearly separable form.
The use of this technique brings significant benefits ranging from reducing the storage space of the dataset to eliminating redundant features, optimising model training time and facilitating data visualisation. However, it is a technique that requires knowledge and appropriate equipment to perform, as more data than necessary may be removed and an erroneous model may be generated.



Comments
Post a Comment